📌 텍스트 기반 워드클라우드 & 가로 막대 차트 생성하기 (Windows 버전)
데이터 분석을 하다 보면 텍스트 데이터를 효과적으로 시각화할 방법이 필요할 때가 많습니다. 특히, 워드클라우드(WordCloud)와 가로 막대 차트(Horizontal Bar Chart) 는 텍스트에서 중요한 키워드를 강조하는 데 유용합니다. 이번 글에서는 Python을 활용하여 워드클라우드와 가로 막대 차트를 생성하는 방법을 설명하겠습니다.
[연습용 데이터]
1️⃣ 라이브러리 준비
우선 필요한 라이브러리를 설치하고 가져옵니다.
import pandas as pd
from konlpy.tag import Okt
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import seaborn as sns
🔹 pandas → CSV 데이터를 다루기 위해 필요
🔹 konlpy.tag.Okt → 한글 형태소 분석을 위한 라이브러리
🔹 collections.Counter → 단어 빈도를 계산하는 데 사용
🔹 wordcloud.WordCloud → 워드클라우드 생성을 위한 라이브러리
🔹 matplotlib.pyplot → 데이터 시각화 도구
🔹 seaborn → 가로 막대 차트를 더 보기 좋게 꾸미기 위해 사용
2️⃣ 불용어 처리 및 데이터 불러오기
워드클라우드를 만들 때 불필요한 단어(불용어, stopwords) 를 제거하는 것이 중요합니다. 보통 자주 등장하지만 의미가 없는 단어(예: "그리고", "하지만")를 제외하면 더 의미 있는 결과를 얻을 수 있습니다.
# 불용어 리스트 파일 경로 설정
stopwords_file_path = 'stopwords-ko.txt'
# 불용어 리스트 로드
with open(stopwords_file_path, 'r', encoding='utf-8') as file:
stopwords = file.read().splitlines()
이제 우리가 분석할 CSV 데이터를 불러옵니다.
df = pd.read_csv("WordCloud.csv")
CSV 파일에는 주로 텍스트 데이터(예: 댓글, 리뷰, 피드백 등) 가 포함되어 있어야 합니다.
3️⃣ 텍스트 전처리 및 명사 추출
한글 텍스트를 분석하기 위해서는 형태소 분석기(Okt) 를 사용하여 명사만 추출하는 것이 일반적입니다.
# 형태소 분석기 객체 생성
okt = Okt()
# 명사 추출 및 불용어 제거
nouns = [noun for comment in df['Comments'] if pd.notnull(comment)
for noun in okt.nouns(comment) if noun not in stopwords]
# 단어 빈도수 계산
word_counts = Counter(nouns)
이제 우리가 분석한 텍스트에서 가장 많이 등장한 단어들을 쉽게 확인할 수 있습니다.
4️⃣ 워드클라우드 생성
이제 본격적으로 워드클라우드 를 생성해봅니다.
# 한글 폰트 경로 설정 (Windows 사용자의 경우)
font_path = 'C:/Windows/Fonts/malgun.ttf'
# 워드클라우드 생성 및 시각화
wordcloud = WordCloud(font_path=font_path, background_color='white',
colormap='Pastel1', width=800, height=800,
max_words=200).generate_from_frequencies(word_counts)
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()
📌 font_path는 한글 폰트 경로를 설정해야 합니다. Windows에서는 malgun.ttf (맑은 고딕)가 일반적이며, Mac 사용자는 AppleGothic.ttf 등을 사용할 수 있습니다.

5️⃣ 가로 막대 차트 생성
워드클라우드만으로는 단어별 빈도를 정확히 파악하기 어려울 수 있기 때문에, 수치적으로 비교할 수 있는 가로 막대 차트도 함께 만들겠습니다.
# 상위 20개 단어 추출
top_words = word_counts.most_common(20)
words, counts = zip(*top_words)
# 가로 막대 차트 그리기
plt.figure(figsize=(12, 6))
sns.barplot(x=counts, y=words, palette="coolwarm")
plt.xlabel("단어 빈도수")
plt.ylabel("단어")
plt.title("가장 많이 등장한 단어 Top 20")
plt.show()
📌 most_common(20)을 사용하여 상위 20개 단어만 추출하여 차트로 표현했습니다.
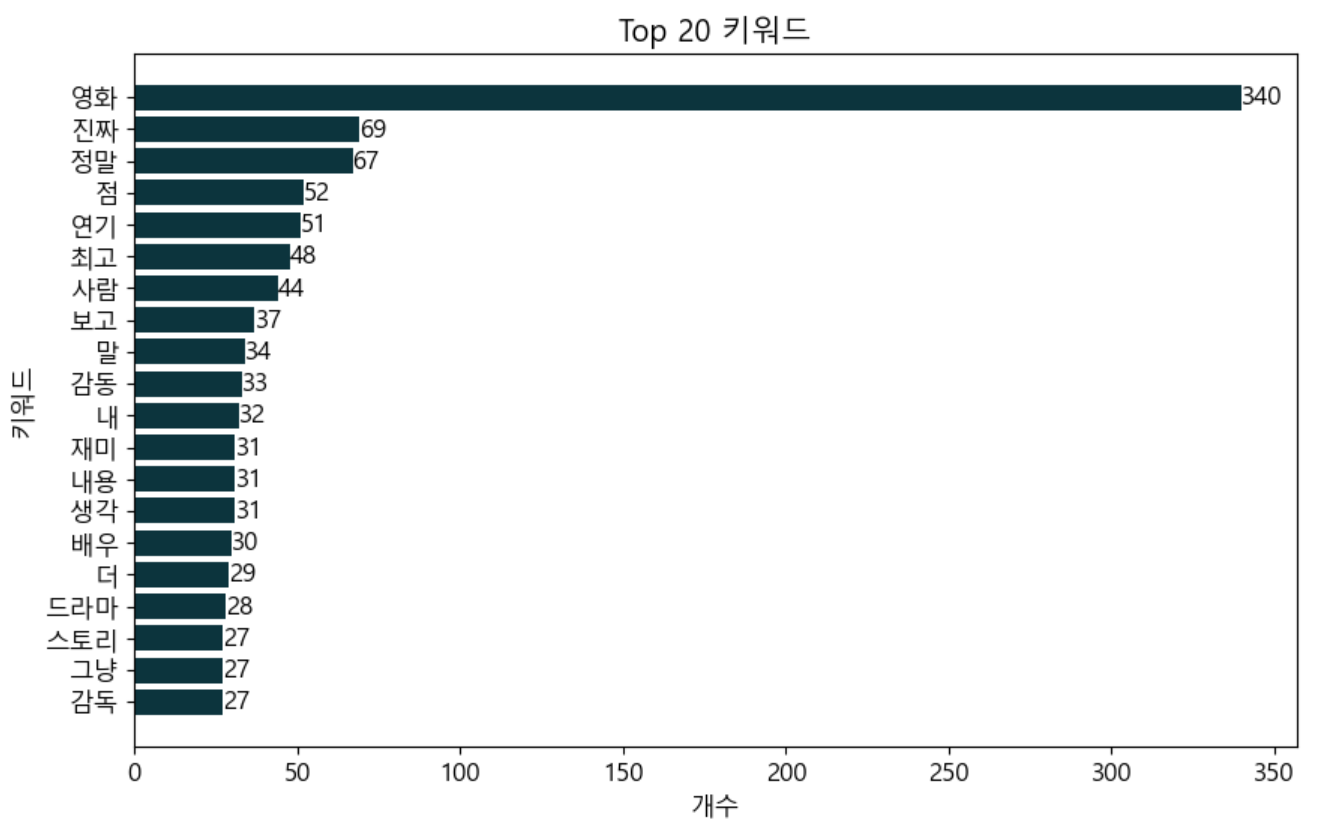
🔥 최종 결과
위의 코드들을 실행하면 다음과 같은 결과를 얻을 수 있습니다.
1️⃣ 워드클라우드 – 텍스트에서 중요한 단어들을 한눈에 볼 수 있음
2️⃣ 가로 막대 차트 – 단어 빈도를 숫자로 비교 가능
이제 여러분의 데이터에 적용해서 텍스트 데이터 분석을 효과적으로 시각화해보세요! 😊
'데이터 시각화(Data Visualization)' 카테고리의 다른 글
| 데이터 시각화 (차트) (0) | 2024.03.12 |
|---|---|
| 워드클라우드(WordCloud, Colab) - 텍스트 시각화 (한글) (0) | 2024.02.27 |

