2024.03.01 - [데이터 분석/판다스(Pandas)] - 판다스 기초 1 (Pandas Basic) - read_csv, drop_durplicate, drop, 기본
지난 시간에는 판다스 기초(Pandas Basic)에 대해 배웠습니다. 오늘은 데이터 전처리에서 자주 사용되는 필터(Filter), 정렬(Sort_values), 병합(Merge), 결합(Concat), 그룹화(Group By)에 대해 학습해보겠습니다. 이번에도 아래의 Google Colab 예제를 복사하여 직접 실습해보시기를 권장드립니다.
Google Colab 예제를 복사하여 아래의 예제를 직접 해보세요.
🗃️데이터 필터 (Conditional filtering)
판다스(Pandas)에서도 엑셀이나 구글 스프레드시트의 필터(Filter) 기능과 유사한 데이터 필터링이 가능합니다. Pandas에서는 '같다'를 나타낼 때 '=' 대신 '=='를 사용하며, '같지 않다'는 '!=' 또는 '~'로 표현합니다.
# 같다 : 예) 시군구 == '관악구'인 경우
df[df['시군구']=='관악구']
관악구를 제외 후 ‘시군구’의 unique() 값을 확인하면 정상적으로 빠져있는 것을 알 수 있다.
# 같지 않다 : 예) 시군구가 '관악구'가 아닌 경우
df[df['시군구']!='관악구']
df[~(df['시군구']=='관악구')]
-----------------------------------
Except = df[~(df['시군구']=='관악구')]
Except['시군구'].unique()
다중 조건 사용하기 AND = & , OR = |
# 관악구에서 카드이용금액계가 50,000이상인 경우 (2가지 조건 AND)
df[(df['시군구']=='관악구')&(df['카드이용금액계(AMT_CORR)']>=50000)].sort_values(by='카드이용금액계(AMT_CORR)',ascending=False)
# '시도'가 제주 이거나, 카드이용금액이 500,000인 경우
df[(df['시도']=='제주') | (df['카드이용금액계(AMT_CORR)']>=5000000)].sort_values(by='카드이용금액계(AMT_CORR)',ascending=False)
⏬ 데이터 정렬 (sort_values)
데이터 분석을 할 때 특정 열의 값을 기준으로 데이터를 정렬하는 것은 매우 중요합니다. Pandas에서는 sort_values() 메서드를 사용하여 데이터를 오름차순 또는 내림차순으로 정렬할 수 있습니다. 예를 들어, 카드 이용 금액을 기준으로 데이터를 내림차순으로 정렬하려면 아래와 같이 코드를 작성할 수 있습니다:
# 카드 이용 금액 내림차순 정렬
sorted_df = df.sort_values(by='카드이용금액계(AMT_CORR)', ascending=False)
만약 여러 열을 기준으로 정렬하고 싶다면, 열 이름과 정렬 방식을 리스트로 지정합니다. 예를 들어, 대분류를 오름차순으로, 카드이용금액을 내림차순으로 정렬하려면 다음과 같이 작성합니다:
# 대분류 기준 오름차순, 카드 이용 금액 기준 내림차순 정렬
sorted_df1 = df.sort_values(by=['대분류', '카드이용금액계(AMT_CORR)'], ascending=[True, False])
더 자세한 내용은 Pandas 공식 문서의 sort_values에서 확인할 수 있습니다.
🔗 병합 (Merge)
데이터 분석 시 여러 데이터 소스를 하나로 합치는 작업이 필요할 때가 많습니다. Pandas에서는 merge() 함수를 사용하여 두 개 이상의 데이터프레임을 특정 키 값을 기준으로 병합할 수 있습니다. 예를 들어, 고객 정보와 거래 내역이 각각 다른 데이터프레임에 저장되어 있을 때, 고객ID를 기준으로 두 데이터를 병합할 수 있습니다


# '고객ID'를 기준으로 왼쪽 조인
merged_df = pd.merge(customers_df, transactions_df, how='left', on='고객ID')만약 병합하려는 데이터프레임의 키 값이 서로 다를 경우, left_on과 right_on 파라미터를 사용하여 각 데이터프레임의 키 값을 지정할 수 있습니다
# 고객 데이터의 '고객ID'와 거래 데이터의 '고객_아이디' 기준 병합
merged_df1 = pd.merge(customers_df1, transactions_df1, how='left', left_on='고객ID', right_on='고객_아이디')
병합에 대한 더 많은 옵션과 자세한 설명은 Pandas 공식 문서의 merge에서 확인할 수 있습니다.
🗃️ Concatenate (concat)
여러 개의 데이터프레임을 하나로 합쳐야 하는 경우가 종종 있습니다. 이때 concat() 함수를 사용하여 데이터를 세로로 또는 가로로 결합할 수 있습니다. 예를 들어, 두 개의 데이터프레임을 세로로 결합하여 모든 데이터를 한 데이터프레임에 통합하려면 다음과 같이 할 수 있습니다:
# 데이터프레임 세로 결합
concatenated_df = pd.concat([df1, df2], axis=0)
concatenated_df
데이터프레임 세로 결합
# 데이터프레임 가로 결합
concatenated_df1 = pd.concat([df1, df2], axis=1)
concatenated_df1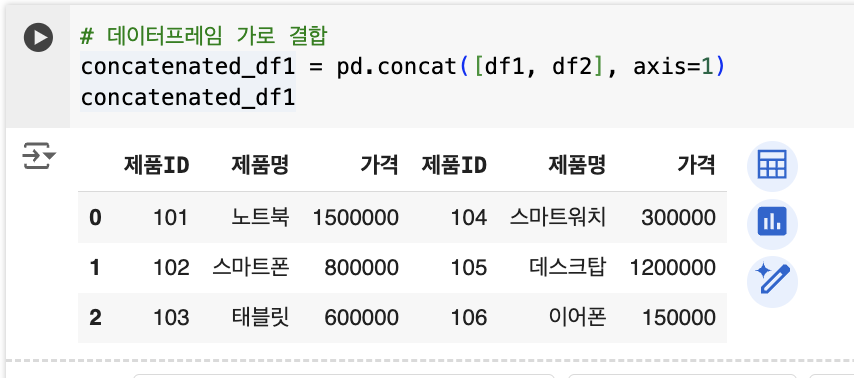
데이터프레임 가로 결합
이 방법은 데이터의 크기가 크거나, 동일한 구조의 여러 파일을 하나로 합쳐야 할 때 매우 유용합니다. 가로로 결합할 경우, axis=1로 설정하면 됩니다.
자세한 사용법은 Pandas 공식 문서의 concat에서 확인할 수 있습니다.
👥 Group by ⭐❗
Pandas의 groupby()는 데이터를 특정 열을 기준으로 그룹화한 후 집계 함수를 적용하여 요약된 결과를 얻을 수 있는 강력한 기능입니다. 예를 들어, 업종별로 카드 이용 금액의 평균, 중앙값, 표준편차를 계산하고자 할 때 다음과 같이 작성할 수 있습니다:
# 업종별 카드 이용 금액의 평균, 중앙값, 표준편차 계산
groupby_df = df.groupby('업종대분류(UPJONG_CLASS1)')['카드이용금액계(AMT_CORR)'].agg(['mean', 'median', 'std'])
이 코드에서는 업종 대분류를 기준으로 그룹화하여 카드 이용 금액에 대해 평균(mean), 중앙값(median), 표준편차(std)를 계산합니다. 그룹화된 데이터를 다양한 방식으로 요약할 수 있어 데이터 분석에 매우 유용합니다.
더 자세한 설명은 Pandas 공식 문서의 groupby에서 확인할 수 있습니다.
𝄜 피벗테이블 (pd.pivot_table)
피벗 테이블은 데이터를 요약하여 다양한 관점에서 분석할 수 있게 해줍니다. Pandas의 pivot_table() 함수를 사용하면 특정 기준으로 데이터를 집계할 수 있습니다. 예를 들어, 월별로 카드 이용 금액의 합계를 계산하고자 할 때는 다음과 같이 작성할 수 있습니다:
# 월별 카드 이용 금액 합계 피벗 테이블
pivot_df = pd.pivot_table(data=df, index='기준일자(YMD)', values='카드이용금액계(AMT_CORR)', aggfunc='sum')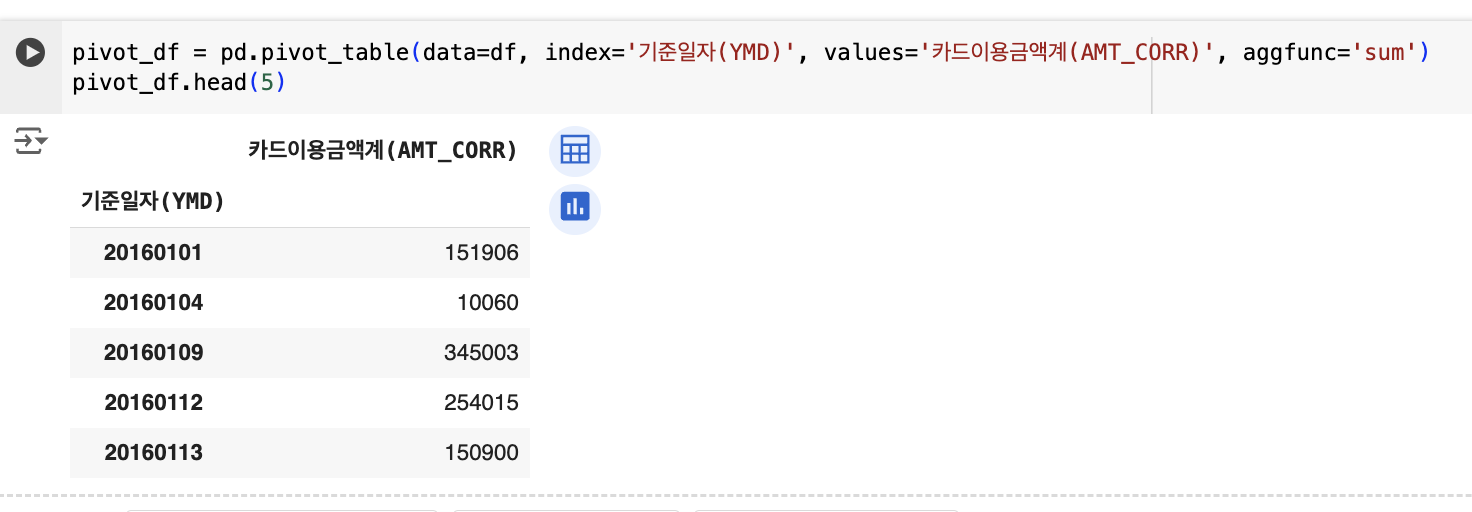
이 코드에서는 기준일자(YMD)를 기준으로 카드이용금액계(AMT_CORR)의 합계를 계산하여 피벗 테이블을 생성합니다. 다양한 집계 함수를 적용할 수 있으며, 데이터를 보다 체계적으로 분석할 수 있습니다.
피벗 테이블에 대한 자세한 내용은 Pandas 공식 문서의 pivot_table에서 확인할 수 있습니다.
'데이터 분석 > 판다스(Pandas)' 카테고리의 다른 글
| 판다스 기초 1 (Pandas Basic) - read_csv, drop_durplicate, drop, 기본 (0) | 2024.03.01 |
|---|
