🐼 판다스(Pandas)란?
판다스는 파이썬에서 데이터 분석을 위한 라이브러리입니다. 주로 표 형태의 데이터를 처리하며, 데이터 가공, 정제, 분석 등을 효율적으로 수행할 수 있습니다. 판다스를 사용하면 대량의 데이터를 손쉽고 빠르게 처리할 수 있으며, 다양한 데이터 분석 기능을 제공합니다.
다음은 제가 생각하는 판다스의 주요 장점입니다:
빅데이터 처리: 판다스를 사용하면, 엑셀이나 구글 시트에서 열 수 없는 매우 큰 데이터(예: 연간 데이터 분석 등)를 처리할 수 있습니다.반복 작업 자동화: 실무에서는 RAW 데이터를 자주 다루며, 같은 작업을 반복하는 것은 비효율적입니다. 판다스를 사용하면 이런 반복 작업을 한 번에 자동화할 수 있습니다 (예: 날짜(Date)를 주(Week)나 월(Month)로 변환, 카테고리 자동 분류 등).데이터 구조 변경(Melt, Groupby 등): 판다스를 사용하면, Wide Form 데이터를 Long Form 데이터프레임으로 변환하는 등 데이터 구조를 자유롭게 변경할 수 있습니다.데이터 병합(Merge) 및 결합(Concat): 100개가 넘는 엑셀 파일 (월별로 정리된 데이터)을 합치는 것은 번거로울 수 있습니다. 그러나 판다스를 사용하면 코드 한 줄로 모든 데이터를 합치고 원하는 필터를 적용하여 분류할 수 있습니다.
이 외에도 판다스는 다양한 장점을 가지고 있어, 사무 및 분석 업무를 수행하는 많은 사람들에게 필수적인 도구입니다.
How do I select a subset of a DataFrame? — pandas 2.2.1 documentation
This tutorial uses the Titanic data set, stored as CSV. The data consists of the following data columns: PassengerId: Id of every passenger. Survived: Indication whether passenger survived. 0 for yes and 1 for no. Pclass: One out of the 3 ticket classes: C
pandas.pydata.org
☑️ Google Colab 예제를 복사하여 아래의 예제를 직접 해보세요.
판다스(Pandas) 기초.ipynb
Colaboratory notebook
colab.research.google.com
⌨️데이터 불러오기 (pd.read_csv)
: 판다스는 CSV, 엑셀 뿐만 아니라 다양한 파일 형식을 읽어 데이터 프레임(Data Frame)을 생성할 수 있습니다.
import pandas as pd #Pandas라는 Library 를 불러와서 pd 라고 이름 지음.
df = pd.read_csv("/content/sampledata/Call_Center.csv")
# 특정 경로에 있는 데이터를 가져올 경우 : r'경로\파일이름.확장자'
# 같은 폴더에 있다면 : titanic = pd.read_csv("data/titanic.csv")
📌Options
✨encoding (참조 사이트)
df = pd.read_csv(r'D:\data.csv', encoding='cp949')
# 한글 폰트 깨지는 경우 : encoding='cp949' 또는 encoding='utf-8-sig'
한글 오류 발생
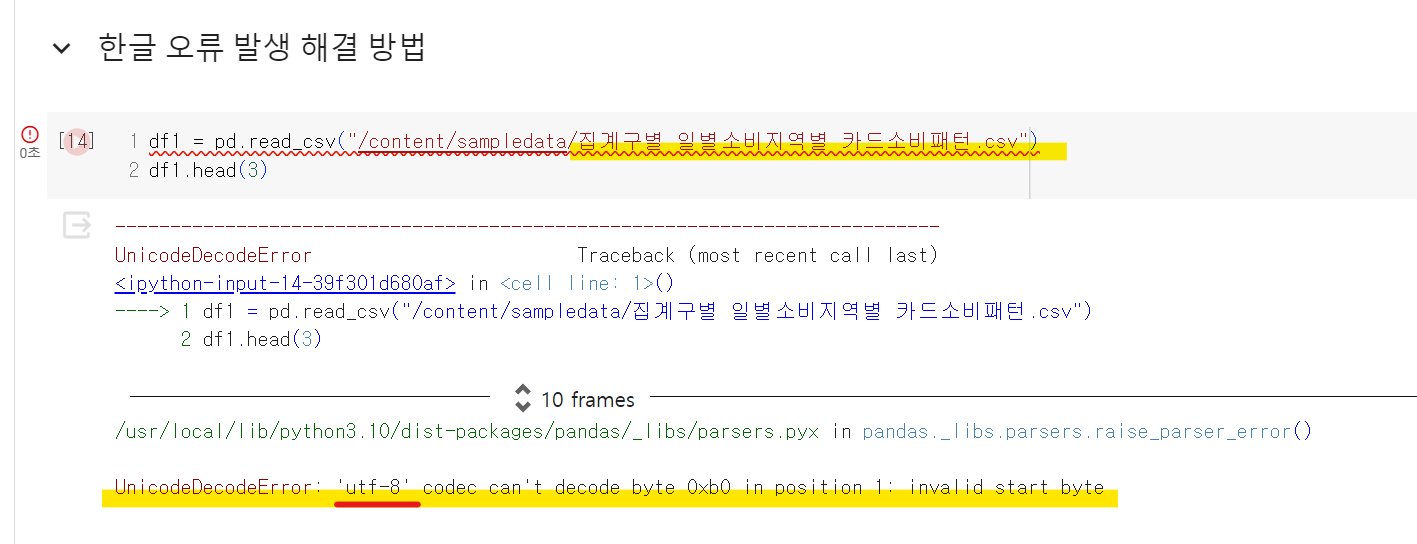
한글 오류 해결

✨skiprows
df = pd.read_excel(r'D:\data.xlsx',skiprows=1)
# skiprows 1 : row를 건너뛰어 불러옴.
✨low_memory : (참조 사이트)
df = pd.read_csv(r'D:\data.csv',low_memory=False)- Error Message : DtypeWarning: Columns have mixed types. Specify dtype option on import or set low_memory=False.
데이터 타입에 NaN 등이 있으면 발생, low_memory=False 로 문제 해결 가능
✨sep
df = pd.read_csv(r'D:\data.csv',sep=',')
# 파일 분류 - CSV(Comma-separated values) 일반적으로 ',' 이지만, 때로는 ';' 로 구분된 경우가 있다. 이런 경우 sep=으로 문제 해결 가능
✨header : Default behavior is to infer the column names: if no names are passed the behavior is identical to header=0 and column names are inferred from the first line of the file.
기본값(Default)이 첫 번째 행을 헤더(Header)로 인식하므로, 크게 사용할 일은 없습니다.
df = pd.read_csv(r'D:\data.csv',header=0)🦾데이터 전처리 (drop_duplicates, drop, fillna, rename etc)
📌Options
✨drop_duplicates() : (공식문서_참고) 중복 값 제거
df.drop_duplicates()- 예문 (
subset&keep활용 예시)
기본적으로, 이는 모든 열을 기반으로 중복 행을 제거합니다.
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
dfdf.drop_duplicates() # 완전히 중복되는 값을 제거
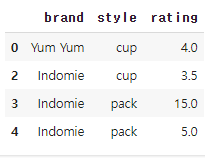
df.drop_duplicates(subset=['brand']) # brand를 기준으로 중복값 찾기


df.drop_duplicates(subset=['brand', 'style'], keep='last') #brand & style 기준으로 중복값 제거 + default는 첫 번째 셀을 선택하지만, 여기서는 마지막 셀 남김

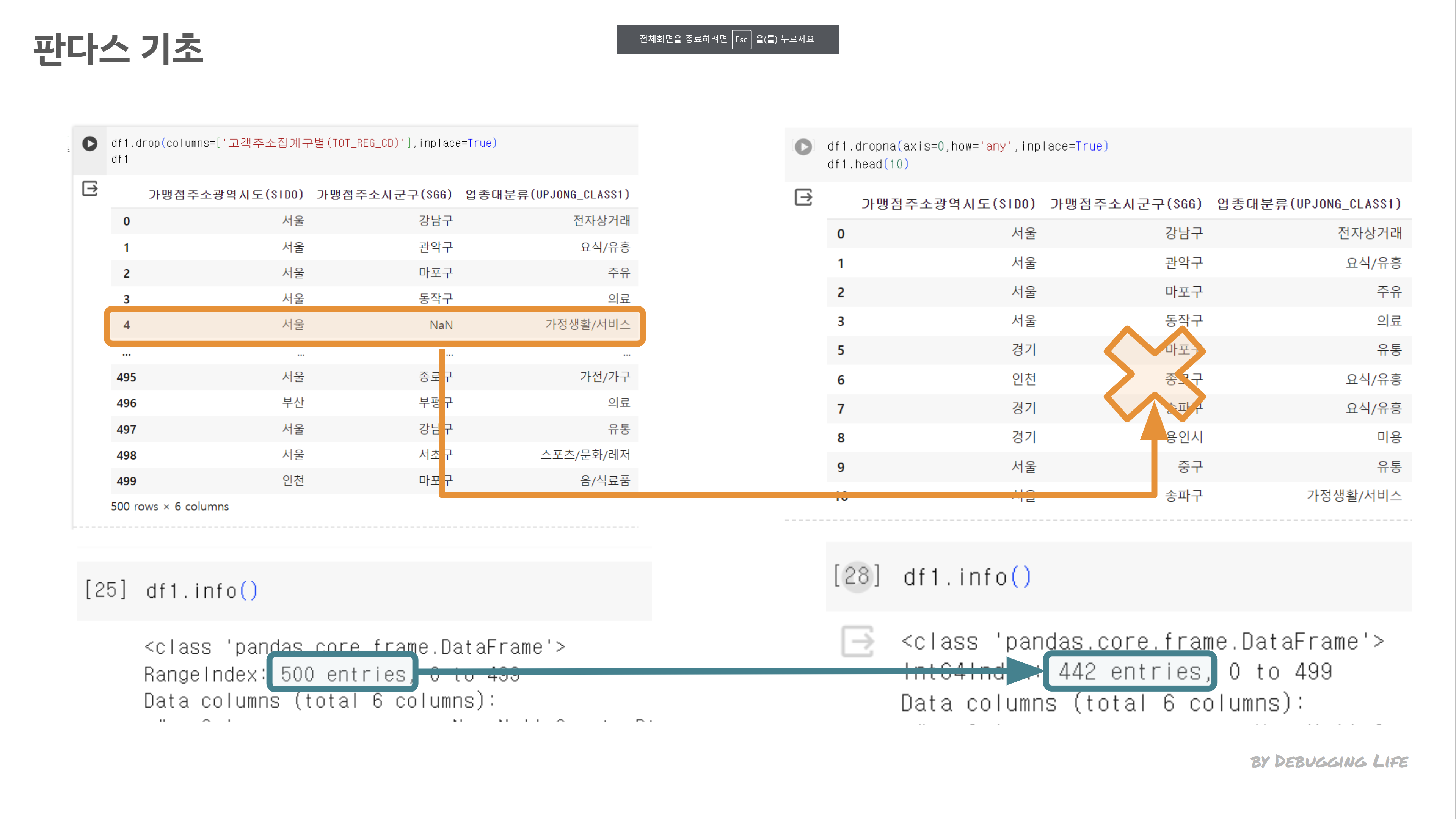
✨drop() & dropna(): Pandas 라이브러리에서 데이터프레임의 특정 행 또는 열을 삭제하기 위해 사용되는 함수입니다. `drop()` 함수는 특정 열 또는 행을 삭제하는데 사용됩니다. 인자로는 삭제하려는 열 또는 행의 이름을 입력하고, axis 인자를 통해 열을 삭제할지 행을 삭제할지를 결정합니다. axis=0은 행을, axis=1은 열을 나타냅니다. 예를 들어, df.drop(columns=['B', 'C'])는 'B'와 'C' 열을 삭제합니다. (공식홈페이지_참고)
df.drop(columns=['B', 'C'])
# df.drop(['B', 'C'], axis=1)
inplace=True

✨dropna() 함수는 누락된 데이터를 가진 행 또는 열을 삭제하는데 사용됩니다. axis 인자를 사용해 행 또는 열을 선택하고, how 인자를 통해 'any' 또는 'all'을 선택하여 하나라도 NaN값이 있는 행 또는 열을 삭제할지 모든 값이 NaN인 행 또는 열을 삭제할지 결정할 수 있습니다. inplace=True를 설정하면 원본 데이터프레임에 변경사항이 바로 적용됩니다. (공식홈페이지_참고)
- how=’
any’ : NaN값이 있는 행 또는 열을 삭제 - how=’
all’ : 모든 값이 NaN인 행 또는 열을 삭제
df.dropna(axis=0, how='any', inplace=True)
Colab 예제 결과를 확인하면, dropna를 통해 NaN값이 있는 행을 제거했다는 것을 알 수 있습니다. 우리가 다루는 데이터가 100% 완전할 것이라는 생각은 처음부터 버리는 것이 좋습니다. 따라서 Pandas를 사용하여 데이터를 미리 정제하면, 더 정확한 분석 결과를 얻을 수 있게 됩니다.
✨fillna() : NaN 값을 다른 것으로 대체하는 것. (공식문서_참고)
df.fillna(0)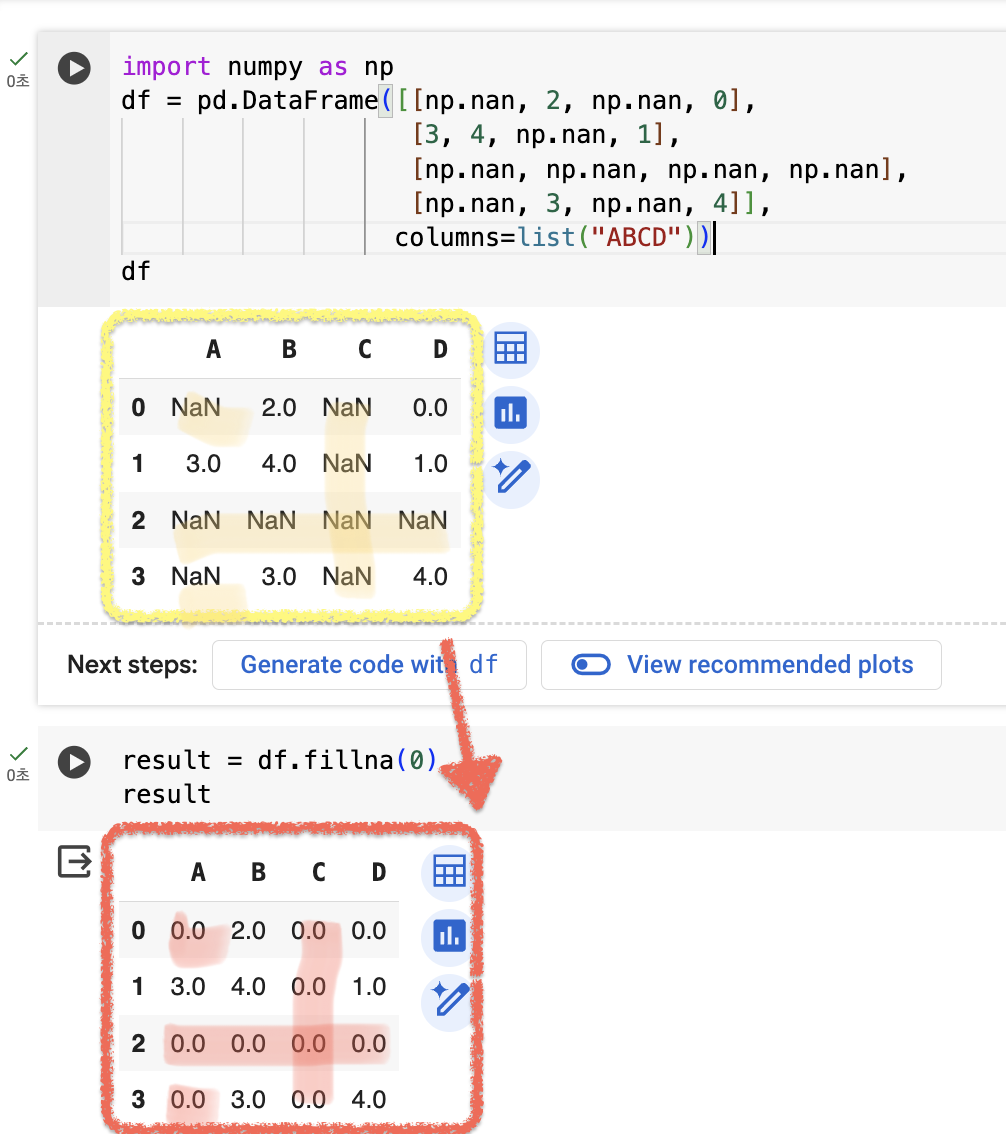
✨rename() :데이터프레임의 행 또는 열 이름을 변경하기 위해 사용됩니다. columns 인자를 사용하여 열 이름을 변경할 수 있으며, 기존 이름과 새 이름을 딕셔너리 형태로 전달합니다.inplace=True를 설정하면 원본 데이터프레임에 변경사항이 바로 적용됩니다.
df.rename(columns={
'가맹점주소광역시도(SIDO)' : '시도',
'가맹점주소시군구(SGG)': '시군구',
'업종대분류(UPJONG_CLASS1)' : '대분류'
}, inplace=True)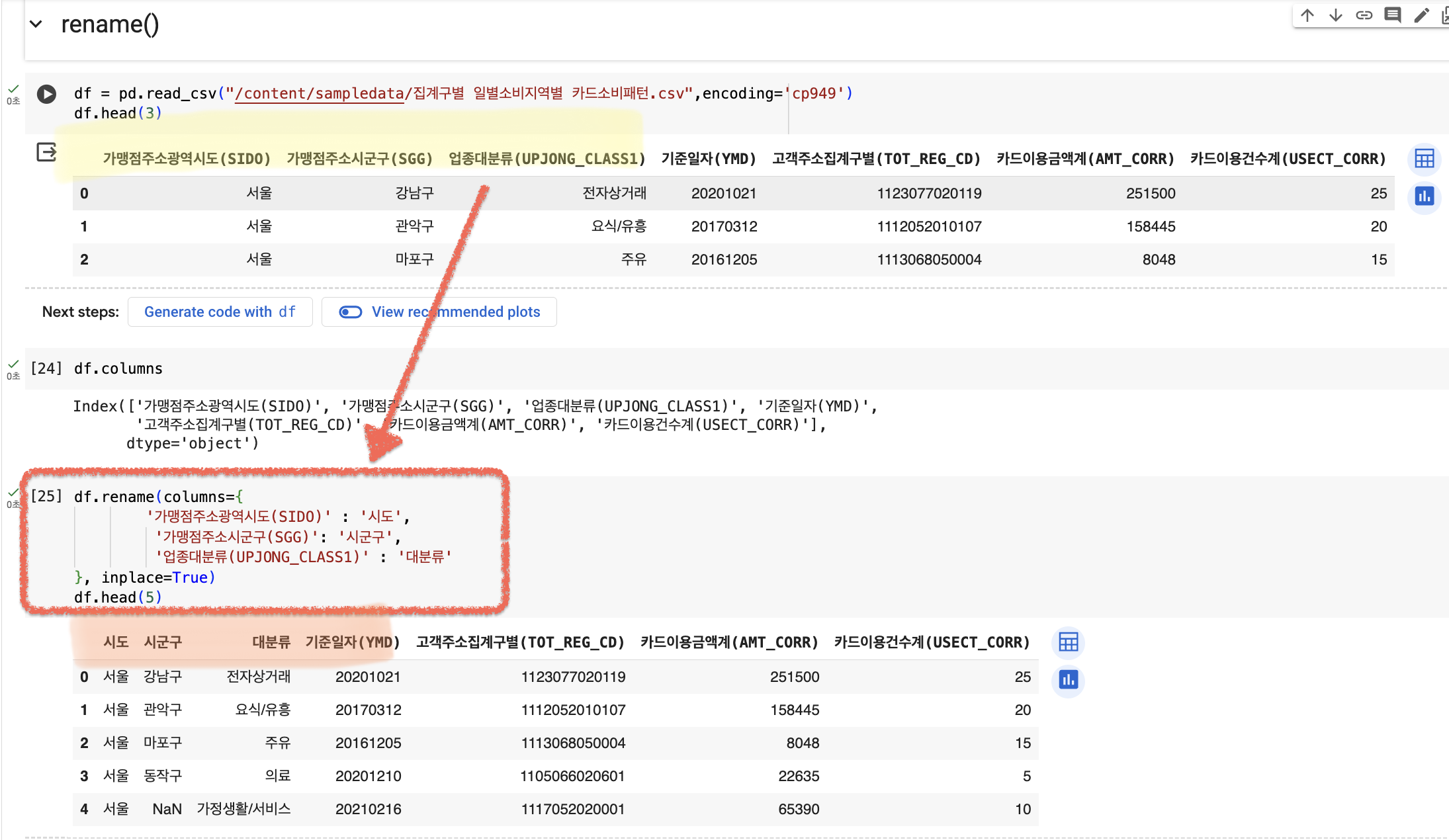
ℹ️기본사항 확인 (예제)
df.shape # RAW 개수 & Column 개수
df.info() # 데이터 타입 확인
df.describe() # 연속형 데이터(숫자)만 뽑아서 Five number Summary를 보여줌
df.head() # 상위 N 개 데이터 출력
df.tail() # 하위 N 개 데이터 출력
df.columns # Column 이름 확인
df.columns.to_list() # Column 전체를 시트화
df['시도'].unique() # 범주형 데이터 항목을 보여줌
df['시도'].value_counts() #범주형 데이터 항목 갯수
기본 내용까지 따라오신다고 고생하셨습니다. 기본 내용이 많아서 나누어 포스팅할 예정이니 예제 파일과 함께 포기하지 말고 학습하시길 바란다.



