728x90
반응형
🎙 Whisper로 STT(음성 텍스트 변환) 하기 – Windows FFmpeg & GPU 설정 가이드
Python + Whisper + FFmpeg + Scoop + GPU (선택)까지 완벽 정리!
✅ 이 글에서 다루는 것
- Whisper 설치 및 실행 방법
- FFmpeg 설치 (PowerShell + Scoop 활용)
- GPU / CPU 환경 모두 대응
- Python 가상환경 구성
- 변환된 결과 엑셀로 저장하기
📋 준비물
| 항목 | 설명 |
|---|---|
| Python 3.10 또는 3.11 | 3.12은 호환성 이슈 있으므로 권장하지 않음 |
| NVIDIA GPU (선택) | GPU 가속을 위한 장치 (예: RTX 4070) |
| FFmpeg | 오디오 전처리 필수 |
| PowerShell | Scoop 설치에 필요 |
| pip | Python 패키지 관리자 (기본 포함됨) |
🧱 STEP 1. Python 설치 (3.11 권장)
python3 --version
py --version🌱 STEP 2. 가상환경 만들기
에러 문구 : activate 명령이 현재 위치에 있지만 이 명령을 찾을 수 없습니다. Windows PowerShell은 기본적으로 현재 위치에서 명령을 로드하지 않습니다.
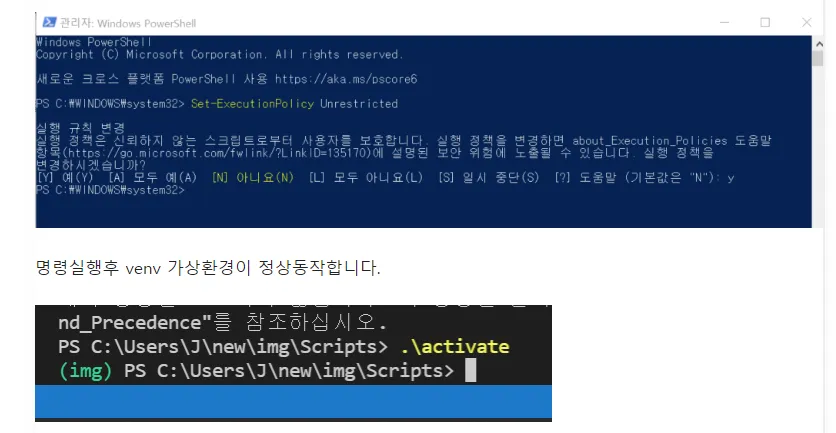
powershell 관리자모드 실행 > Set-ExecutionPolicy Unrestricted 입력
## 가상 환경 만들기
python -m venv myenv
- whisper-env 대신에 아무거나 써도 된다.
## 가상환경 들어가는 방법
1. 가상 환경을 생성한 Scripts 폴더로 이동한다.
-> cd myenv\Scripts
2. activate 명령어를 입력한다.
-> .\activate
입력 후 프롬프트가 이렇게 바뀜:
(myenv) C:\...>
→ 그러면 성공적으로 가상환경에 들어간 거야!

🔌 STEP 3. FFmpeg 설치 (Scoop 활용)
# PowerShell에서 스크립트를 실행할 수 있도록 허용해주는 명령
Set-ExecutionPolicy RemoteSigned -scope CurrentUser
# 이건 Scoop이라는 윈도우용 패키지 매니저를 설치하는 명령어야.
irm get.scoop.sh | iex
scoop install ffmpeg
ffmpeg -version🧠 STEP 4. PyTorch 설치
GPU:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
CPU:
pip install torch torchvision torchaudio
확인:
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))📦 STEP 5. Whisper 설치
pip install openai-whisper🧪 STEP 6. Whisper CLI 사용 예시
whisper "C:\Users\YOU\Desktop\audio.wav" --model medium --language Korean
📊 STEP 7. Python 코드로 STT + Excel 저장
import whisper
import pandas as pd
import datetime
import os
def format_time(seconds):
return str(datetime.timedelta(seconds=int(seconds)))
# Whisper 모델을 CPU에서 로드
print("Loading Whisper model on CPU...")
model = whisper.load_model("medium", device="cpu")
# 오디오 파일 폴더 경로 (문자열 앞에 r 붙여서 경로 오류 방지)
folder = r"audio"
results = []
# 폴더 내 오디오 파일 탐색 및 전사
for file in os.listdir(folder):
if file.endswith(('.wav', '.mp3', '.m4a')):
path = os.path.join(folder, file)
print(f"Transcribing: {file}")
result = model.transcribe(path, language="ko")
# 시간 구간별 텍스트 정리
segments = []
for seg in result['segments']:
segments.append(f"[{format_time(seg['start'])} - {format_time(seg['end'])}] \"{seg['text'].strip()}\"")
results.append({
"filename": file,
"transcript": "\n".join(segments)
})
# 현재 날짜를 YYYYMMDD 형식으로 가져오기
current_date = datetime.datetime.now().strftime("%Y%m%d")
# 파일 이름 생성
file_name = f"{current_date}_results.csv"
output_path = os.path.join('.', file_name) # 상위 폴더로 이동
# DataFrame을 CSV로 저장
df = pd.DataFrame(results)
df.to_csv(output_path, index=False, encoding='cp949')
print(f"\n✅ 전사 완료! 결과 저장 위치: {output_path}")❗ 자주 발생하는 오류 & 해결법
| 오류 메시지 | 해결 방법 |
|---|---|
| 'ffmpeg'은(는) 내부 명령어가 아닙니다 | Scoop 또는 수동 설치 + 환경변수 등록 |
| torch.cuda.is_available() = False | GPU용 PyTorch 미설치. cu121 버전으로 재설치 |
| %1은 올바른 Win32 응용 프로그램이 아닙니다 | Python 3.12와 PyTorch GPU 충돌. 3.10~3.11 권장 |
| FileNotFoundError | 전체 경로 지정 필요 |
🔗 참고 링크
🔊 한국어 음성 샘플
- 📚 AI-Hub – 한국어 강의 음성 데이터
EBS 교육 영상 기반의 고품질 강의 음성 데이터. AI 학습이나 교육 콘텐츠 제작에 적합.
728x90
반응형



